
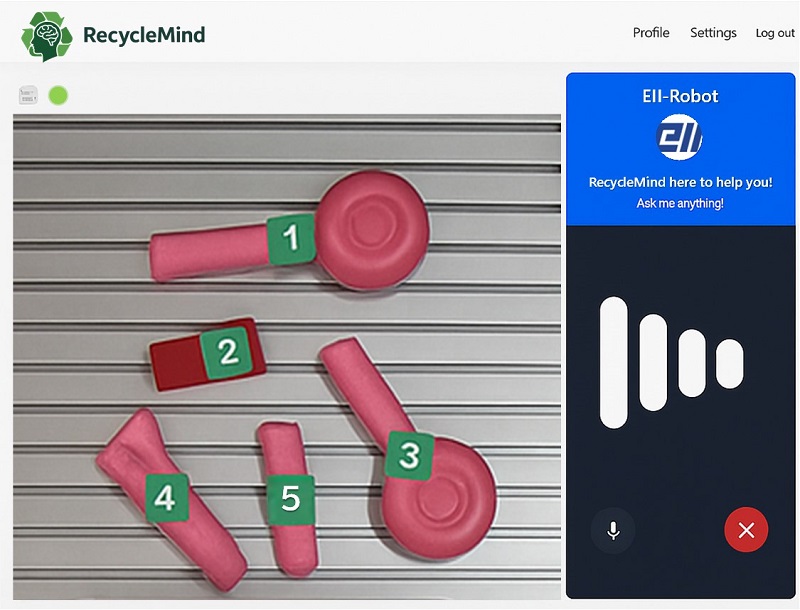
当社では、最先端の大規模マルチモーダルモデル(LMM: Large Multimodal Models)を活用した画像認識システムを開発・提供しています。このシステムは、画像とテキストなど異なる情報モダリティを統合的に処理する高度なAIモデルにより、従来の画像認識を大きく超える柔軟性と精度を実現しています。その特長を以下に整理します。
| 高度な認識性能 | 数億~数百億のパラメータを持つ大規模モデルにより、物体・シーン・状況・文字情報などを統合的に理解。現場での微細な違いも高精度に識別可能です。 |
|---|---|
| マルチモーダルな理解 | 画像に加え、テキストや音声など複数の情報を統合して処理することで、文脈に基づいた認識や対話的な応答が可能になります。 |
| 多様な用途に対応 | 製造・物流・廃棄物処理・小売・医療など、さまざまな業種での活用を想定。用途に応じてカスタマイズが可能です。 |

①言語理解+②画像認識+③ロボット制御